



#ai
#StarSearch
#Workspaces
Every GitHub Repository Should Be A Dataset
BekahHW
6 mins read

GitHub recently claimed the top spot in Gartner's inaugural Magic Quadrant for AI Code Assistants. In mid-2021, GitHub made waves by entering the AI-powered code completion market. While competitors had already offered similar solutions, GitHub's strategic partnership with OpenAI proved highly successful. This move not only positioned GitHub as a leader in AI-assisted development but also led to the company redefining its core focus around AI technologies.
Today we have seen the projects like Cursor, Magic, and Sourcegraph’s Cody enter the space to compete in providing developers with the best AI coding companion. With GitHub being the leader among so many competitors, what's next in the space to stay competitive?
Interestingly, while these AI coding assistants focus on code completion and generation, there seems to be a missed opportunity in leveraging the contextual information available in GitHub issues and discussions. GitHub repositories contain a wealth of knowledge about problem-solving approaches, best practices, and domain-specific insights. Why aren't AI companies exploring ways to collect and share this valuable context? Incorporating this information could significantly enhance the AI assistant's understanding of real-world development challenges and provide more nuanced, project-specific assistance to developers. This missed opportunity could be the key to unlocking the next level of AI-assisted development.
The Untapped Potential of Repository Data
Every GitHub repository is more than just lines of code. It's a rich ecosystem of issues, discussions, pull requests, comments, and documentation. These elements collectively tell the story of a project's evolution, capture the reasoning behind decisions, and document the collective knowledge of contributors.
By leveraging this contextual data, AI assistants could provide more nuanced, project-specific insights and suggestions. Imagine an AI coding assistant that doesn't just complete your code, but understands the history of your project, the rationale behind previous decisions, and the unique challenges your team has faced.
Consider this example: When asked about the top contributors to ArgoCD, ChatGPT provides a general response:
"The top contributors to the Argo CD project frequently change as it is an active and collaborative open-source community. Currently, some of the most significant contributors include individuals from Intuit and other active community members. However, the specific top contributor at any given time can vary depending on recent contributions and involvement in the project."
While this answer is not incorrect, it lacks specificity and real-time accuracy. But if we add ArgoCD to an OpenSauced Workspace, we can ask StarSearch, OpenSauced's AI, the same question and get a more detailed response:
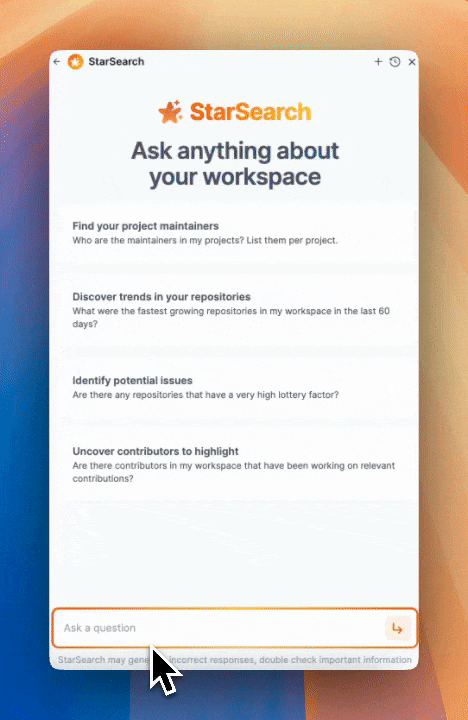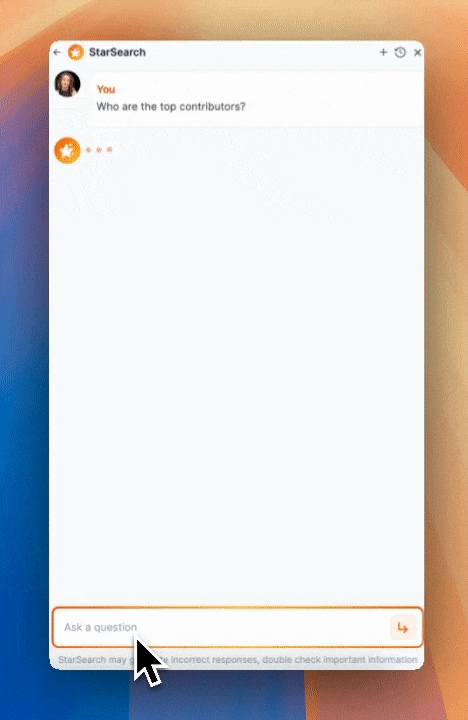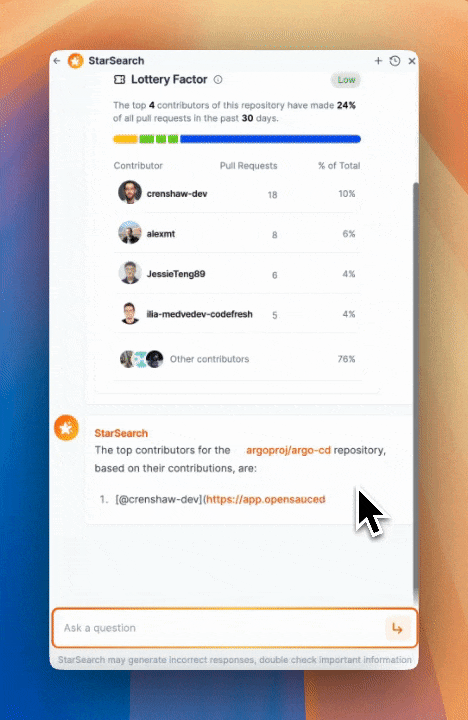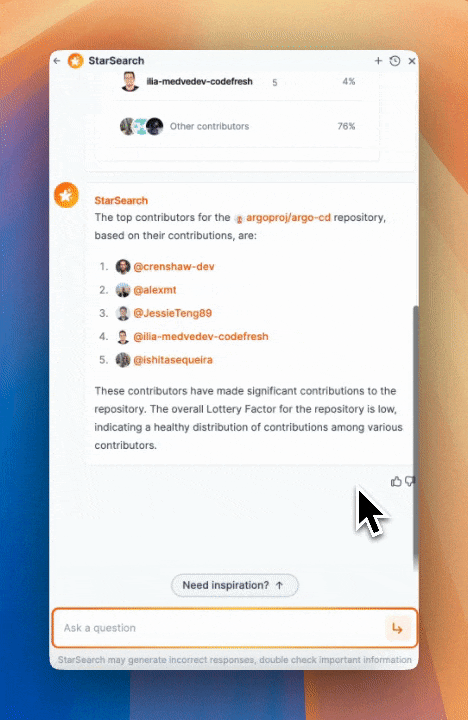
Not only do we see the top contributors, but we get a breakdown of the number of contributions and more context about the lottery factor - the number of contributors that would need to suddenly leave to cause an impact on the project.
The Vision: Every GitHub Repository as an AI-Ready Dataset
Extending the Workspace concept to all GitHub repositories means that every repository could become a rich, context-aware dataset ready for AI analysis. For many projects, repositories are living records of the software development lifecycle. From the first commit to debugging and refactoring, repositories capture a wealth of information. By treating these repositories as comprehensive datasets, we unlock a new possibilities for AI-assisted development.
Knowledge Transfer
AI models trained on repository data can learn not just how to generate code, but why certain decisions were made. With access to issues and discussion, context about how problems were solved in the past and what trade-offs were considered allows for more informed answers to queries. This deep learning allows AI to transfer knowledge across projects and teams, potentially accelerating problem-solving and innovation.
For instance, if an AI assistant could analyze commit messages, pull request discussions, and issue threads to understand the reasoning behind architectural decisions, it could apply this knowledge to suggest solutions for similar challenges in new projects or adjacent domains.
Contextual Understanding
By incorporating context from issues, discussions, and code reviews, AI assistants can provide more nuanced recommendations that go beyond syntax to understand intent. This context-aware AI could offer suggestions that align with project goals, coding standards, and team preferences.
Imagine an AI assistant that, before suggesting a code change, considers the project's performance requirements, security policies, and even the team's preferred coding style - all extracted from the repository's history and documentation.
Practical Use Case: AI and Repository Context
Let's revisit our earlier example of asking about top contributors to a project like ArgoCD. While current AI models provide generalized responses, a context-aware AI could deliver far more insightful information.
Imagine asking, "Who are the top contributors to ArgoCD, and what areas do they focus on?" This is what we get when we ask StarSearch on the ArgoCD Workspace:
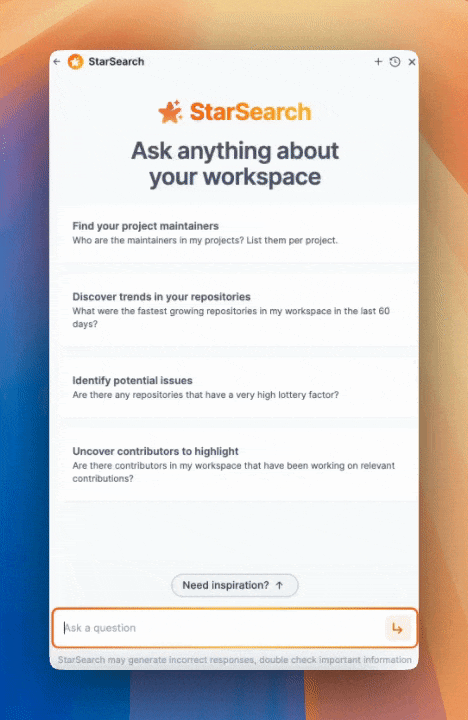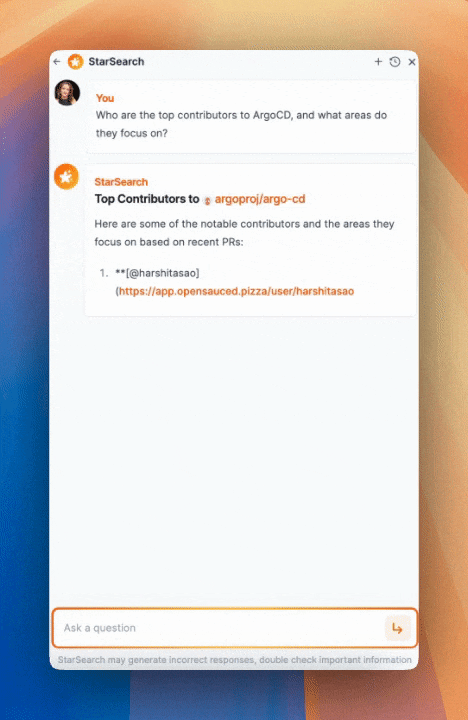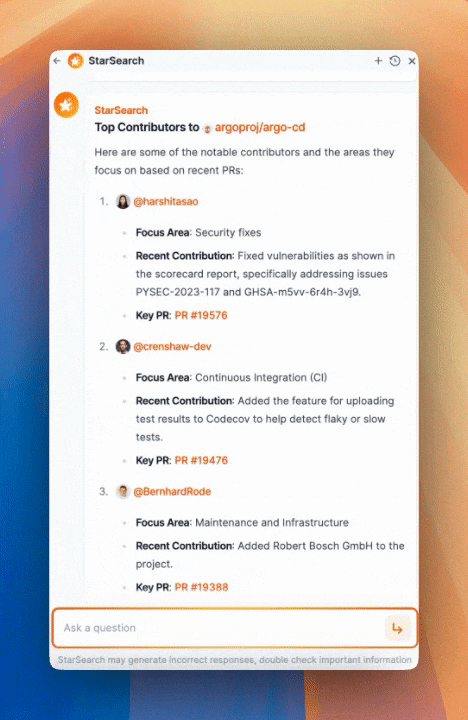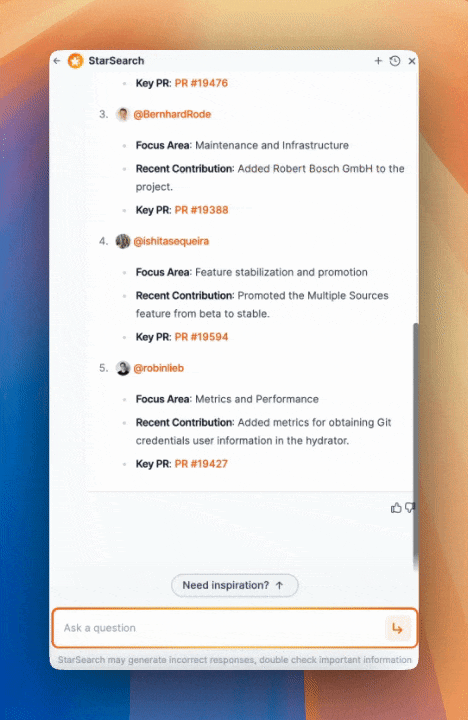
We see a more detailed breakdown of the types of contributions and who was responsible for key changes.
Multi-Repository Workspaces: A Unique Dataset for AI
But an even more powerful approach to treating repositories as a dataset happens when we group multiple repositories together - something you can do today in a Workspace. This approach creates a unique, interconnected dataset that provides a broader context for AI analysis.
Creating a Comprehensive Dataset
By aggregating multiple repositories into a single workspace, we create a dataset that captures not just isolated project information, but the relationships and patterns across different projects. This comprehensive view would allow for:
- Identifying cross-project patterns and best practices
- Understanding dependencies and interactions between different repositories
- Analyzing how different teams or projects approach similar problems
Benefits of Multi-Repository Datasets
Multi-repository workspaces provide a comprehensive view of complex projects, revealing interactions between different components and enabling deeper insights into system-wide patterns. This comprehensive view encourages the cross-pollination of ideas, allowing AI assistants to suggest improvements or solutions from one project that could benefit another. Additionally, by analyzing multiple repositories simultaneously, you could identify inconsistencies in coding standards or practices across projects, presenting opportunities for standardization and overall code quality improvement.
Using multi-repository workspaces as datasets also allows us to learn:
• Organizational Patterns: How different teams within an organization approach problem-solving, code organization, and collaboration.
• Technology Adoption Trends: How new technologies or methodologies spread across different projects within an organization.
• Knowledge Flow: How information and best practices propagate between different repositories and teams.
• Project Health Indicators: By comparing metrics across repositories, we can identify what factors contribute to project success or struggle.
AI assistants could suggest collaborations by understanding the expertise demonstrated across different repositories, recommending potential partnerships between team members or projects. There's also potential to predict integration challenges, based on historical data. And lastly, security analysis could be enhanced, with AI assistants identifying vulnerabilities. For instance, this could be done by creating an SBOM from your Workspace to understand the dependencies and vulnerabilities across your projects.
The Next Competitive Edge in AI Development
As AI tools for software development continue to advance, the ability to capture the collective knowledge embedded in GitHub repositories will become an important differentiator. The future of AI in this space isn't just in generating code, but in understanding the rich context surrounding that code.
Companies that can effectively implement this repository-as-dataset approach will have a significant competitive advantage. Their AI tools won'y just be faster at generating code, but smarter at understanding the why behind the code, leading to more valuable and contextually appropriate assistance.
You can build your own AI-ready dataset by creating a Workspace today. You can also check out my ArgoCD Workspace or, for a multi-repository example, The TanStack Workspace.

BekahHW
Bekah graduated from a coding bootcamp in May of 2019 and since then has spent time as a frontend developer, started the Virtual Coffee tech community, spent time in DevRel and has continued to mom her four kids. She currently co-hosts the Compressed.fm and Virtual Coffee podcasts, lifts heavy things in her free time, & works as the Developer Experience Lead at OpenSauced.
Recent Posts

#pizza cli
BekahHW
5 mins read
As projects grow and teams change, tech companies accumulate "knowledge debt." By adding code ownership practices and tools like the pizza-clicodeowne...

#command line
John McBride
5 mins read
A powerful way to generate and automate developer insights from the command line
Subscribe for Extra Sauce
Stay up to date with the latest OpenSauced news and trends.



